Working with Pipeline:
This section provides detailed instructions on the process of creating a new Pipeline and importing data into the designated connector. Prior to this, it is essential to properly configure the Data Store in order to proceed with the subsequent steps.
Steps for Creating New Pipeline:
To add a new Pipeline, navigate to the left side panel and click on the “Add Pipeline” button

Note: Pipeline name using only alphanumeric characters and click on the
tickicon to confirm and save the Pipeline details.
Provide the designated Pipeline name and proceed by selecting the confirm icon. Subsequently, select the Pipeline name to proceed with further actions.

You will be directed to the Extract page where you can configure the settings for the source connector.

Extract:
The source data source connector can be configured in a YAML file format. The data source name is displayed in the Connector list panel, where the user can select the connector name and click on Add Template to access sample configuration details. Multiple connectors can be added to a Pipeline to transfer data to a destination database.
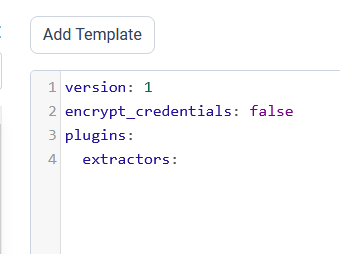
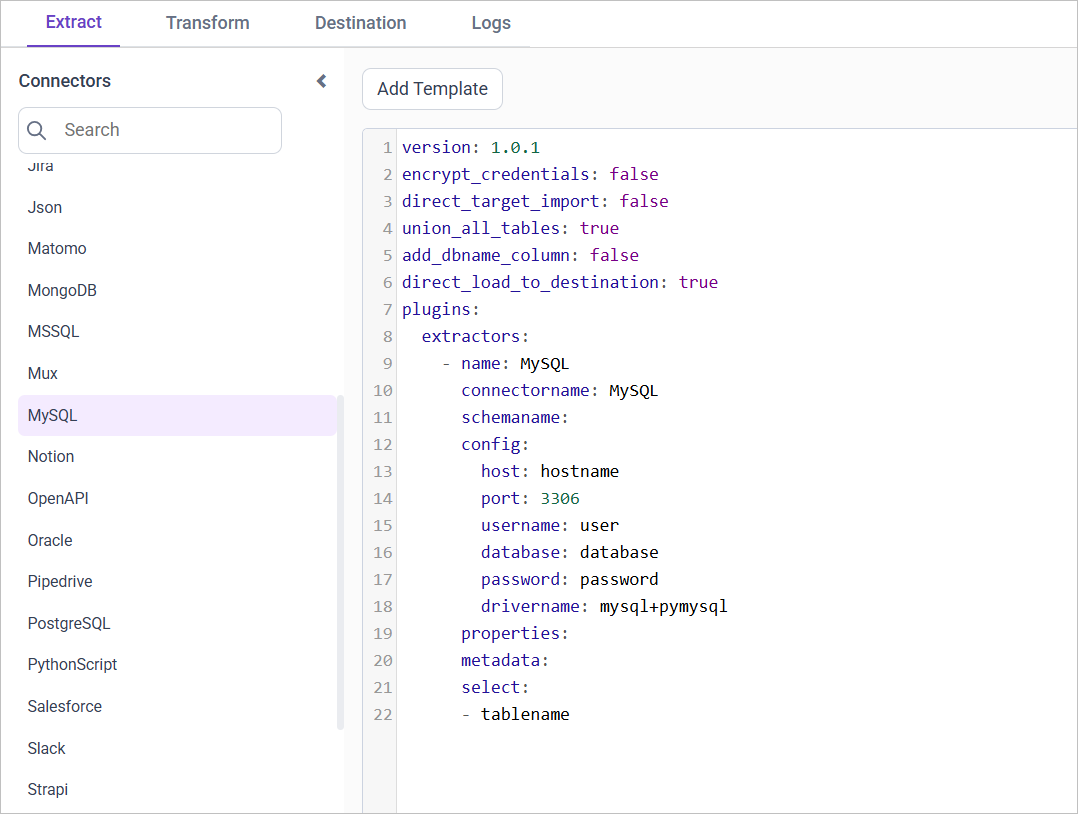
Example: Configuration File
version: 1.0.1
encrypt_credentials: false
plugins:
extractors:
- name: MySQL
connectorname: MySQL
schemaname:
config:
host: localhost
port: 3306
username: root
database: sakila
password: +NQCHLZ1l/RaR1L0HK+0jg==
drivername: mysql+pymysql
select:
- inventory
- payment
- name: PostgreSQL
connectorname: PostgreSQL
schemaname: test
config:
host: localhost
port: 5438
username: postgres
database: demo
password: +NQCHLZ1l/RaR1L0HK+0jg==
drivername: postgresql+pg8000
select:
- ticket_metricsAfter clicking the Save button, a popup window will appear. Within this window, locate and click on the dropdown menu labeled Select Destination. From the options provided, choose the specific DataStoreName that has been previously configured in the Data Store settings page.

Next, navigate to the “Schedule” page on the platform and select the “Run Now” option to initiate the desired action immediately.
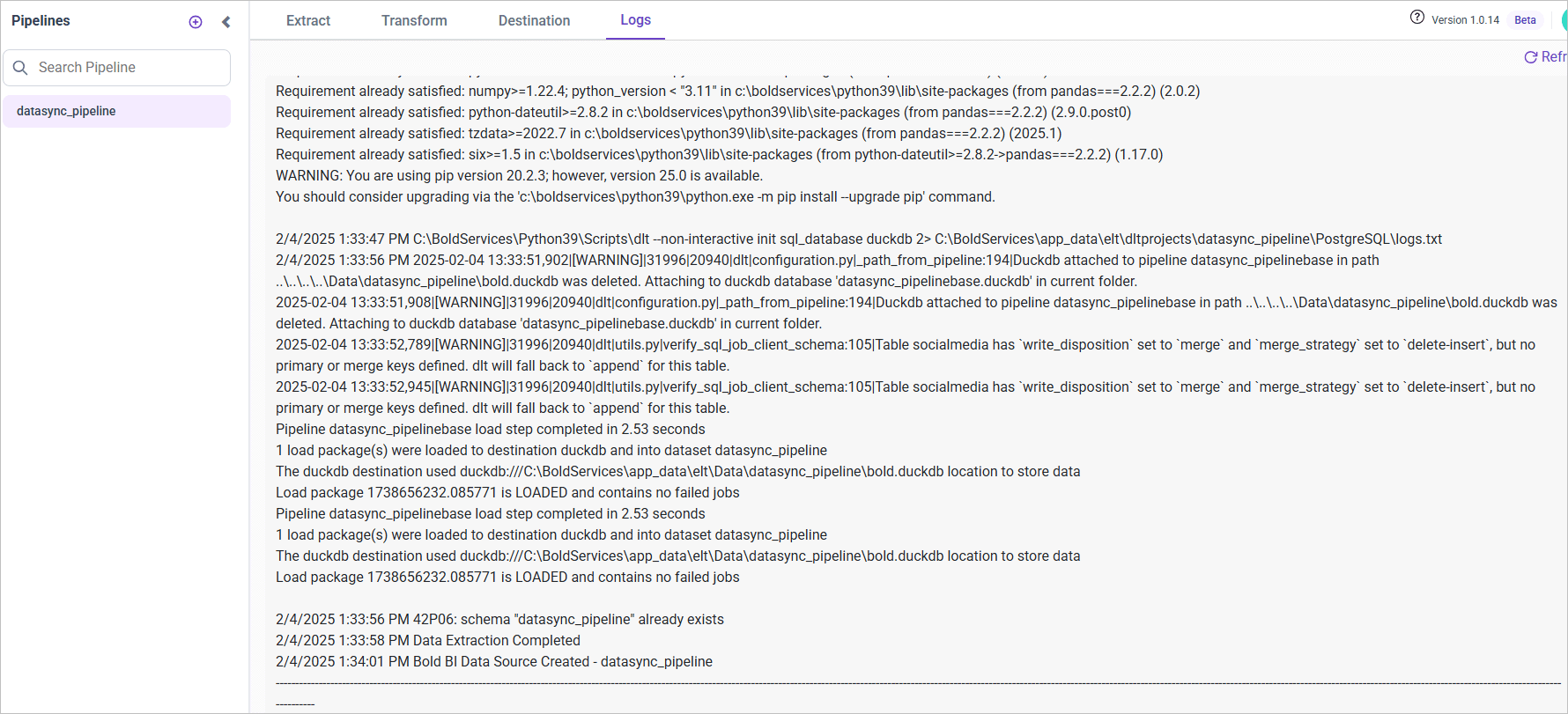
Upon the completion of the project, a data source will be generated within the platforms of “Bold BI” or “Bold Reports.”

Please refer to the current operational status by accessing the information displayed in the “Logs” tab.
Pipeline Properties
Drop table
isDropTable
Description:
Controls whether existing tables in the destination are dropped and recreated during pipeline execution.
- true (Default) — If the table exists, it is dropped and recreated before loading fresh data.
- false — Tables are created only if they don’t exist, and data is inserted/appended without dropping.
When/Why to Use:
- Set to true for full refreshes, where historical data is not needed and a clean schema is desired.
- Set to false for incremental loads or when preserving data continuity is critical (e.g., production append-only workflows or pipelines using upserts when a primary key is defined).
- Dropping tables helps handle breaking schema changes by recreating tables with updated structures.
Note:
- Applied across all supported datatores.
- This property is not applicable when a primary key is explicitly defined, as existing tables are updated through upsert operations instead of being dropped and recreated.
- In some versions (e.g., pre - 1.0.21), this was not configurable -always check version compatibility.
Direct load to destination
direct_load_to_destination
Description:
Determines the data flow path: whether data should be moved from a staging layer (DuckDB) to the target datastore or remain in staging.
- true (default) — data is first loaded into DuckDB (staging) for transformation and then moved to the target datastore.
- false — data is loaded into DuckDB for transformation but is not moved to the target datastore, only transformed data can be moved later to target datastore (via the transform option in DataHub).
When/Why to Use:
- Set to true when you want the full data flow — from source → staging (DuckDB) → destination.
- Set to false when you want to keep only the transformed data in staging (DuckDB) and avoid automatic movement to the destination.
Note: Applied across all supported datatores.
Direct target import
direct_target_import
Description:
Determines whether data should be moved directly to the target datastore or processed first through a staging layer before being exported (DuckDB → Parquet → destination).
- false (default) — data is first loaded into DuckDB (staging) and then exported as Parquet files and moved to the destination using bulkupload .
- true — data is sent directly to the destination datastore without using the staging layer.
When/Why to Use:
- Prefer false (staging + Parquet) for large datasets, because exporting optimized Parquet files from DuckDB and bulk-loading them can be faster.
- Prefer true for simple extracts or connectors that support efficient direct ingestion.
Note:
- This property is supported for Amazon Redshift, Google BigQuery and Snowflake.
- Amazon S3 is required for the staging + Parquet workflow only when the destination is Amazon Redshift.
- For MSSQL, direct_target_import is supported only when the connector type is also MSSQL.
Set not null as primary keys
set_not_null_as_primary_key
Description:
Determines whether columns that contain no null values in DuckDB should be automatically treated as primary keys in the destination when no explicit primary key is defined.
- true — After data is loaded to DuckDB, each column is scanned; columns with no nulls are treated as primary keys.
- false — No automatic inference from data; primary keys must be provided explicitly.
If a column contains no nulls (even if it’s not explicitly defined as NOT NULL in the schema), it is automatically promoted as a primary key candidate in the destination.
When/Why to Use: Use this when importing from sources that often lack explicit primary keys (CSV, JSON, or semi-structured data). It helps auto-detect candidate keys and reduces manual configuration.
Behavior & Caution:
- The process inspects actual data (not only schema metadata) to find columns with no nulls.
- Columns with internal DLT metadata (e.g., _dlt_id, _dlt_parent_id) are excluded from inference.
- Caution: A column that contains no nulls may still be non-unique — promoting such a column to a primary key can cause correctness or constraint errors in the destination.
Note:
| Supported Datastores | Not Supported Datastores |
|---|---|
| Apache Doris | Amazon Redshift |
| Google BigQuery | Azure Synapse |
| MySQL | ClickHouse |
| Oracle | Firebolt |
| PostgreSQL | IBM DB2 |
| SQL Server | MinIO |
| Snowflake | SAP HANA Cloud |
| Teradata |
Configuring Primary Keys for Connectors
The primary_keys property in the extractor’s properties section allows you to define custom primary keys for the tables being extracted. This property specifies which column(s) should be used as primary key(s) in the destination table.
Syntax:
properties:
primary_keys: '{table_name_1}: {key_1}, {key_2}; {table_name_2}: {key_3}'Example:
properties:
primary_keys: 'customers: customerId, firstName;orders: orderId'For the customers table: primary keys are customerId and firstName (composite key) For the orders table: primary key is orderId
Behavior:
- The property is expected to be a string with semicolon-separated table specifications and comma-separated keys.
- Table names must match those in the extractor’s
selectlist. - Multiple keys per table are supported (composite primary keys), assuming the destination database allows them.
- If
primary_keysnot specified,check forset_not_null_as_primary_keyproperty is true column with no nulls values are set as PK or tables remain without primary keys.
Important: Ensure the column names are correct and present in the table schema. Mismatched columns may cause data extraction errors.
Note:
| Supported Datastores | Not Supported Datastores |
|---|---|
| Apache Doris | Amazon Redshift |
| Google BigQuery | Azure Synapse |
| MySQL | ClickHouse |
| Oracle | Firebolt |
| PostgreSQL | IBM DB2 |
| SQL Server | MinIO |
| Snowflake | SAP HANA Cloud |
| Teradata |
Example: MySQL Connector with Primary Keys
version: 1.0.1
encrypt_credentials: false
direct_target_import: false
union_all_tables: true
add_dbname_column: false
direct_load_to_destination: true
use_snake_casing: true
set_not_null_as_primary_key: false
plugins:
extractors:
- name: MySQL
connectorname: MySQL
schemaname:
config:
host: localhost
port: 3306
username: root
database: work
password: <password>
drivername: mysql+pymysql
properties:
primary_keys: 'customers: customerId, firstName;orders: orderId'
select:
- customers
- ordersDelete Pipeline:
To delete a Pipeline, navigate to the left side panel and click on the Delete icon corresponding to the selected pipeline.
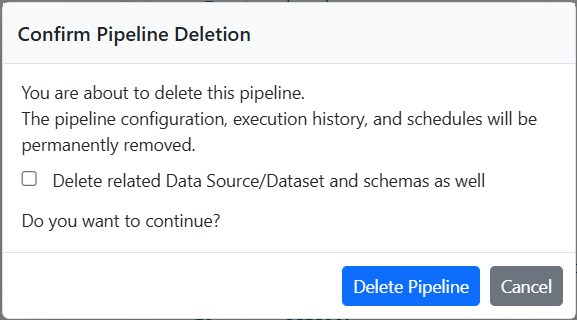
When you attempt to delete a pipeline, a confirmation popup will appear.
- You can use the checkbox to decide if the associated data source and schema should be deleted or not along with the pipeline.
- Click the DeletePipeline to proceed with the deletion.
- Clicking the Cancel button will close the dialog and stops the deletion process.
What Happens After Deletion
If the checkbox is selected
- The selected pipeline will be permanently removed from the Pipelines list.
- The datasource created for the pipeline in Bold BI will be deleted.
- The schema and its tables associated with the pipeline will also be deleted in the selected destination.
If the checkbox is not selected
- The selected pipeline will be permanently removed from the Pipelines list.
- The datasource and schema created for the pipeline in Bold BI will not be deleted.